語言建模是自然語言處理(NLP)的核心技術,旨在通過統計或神經網絡模型預測文本序列的機率分佈。其應用涵蓋語音識別、機器翻譯、文本生成等領域。現代語言模型經歷了從基於規則的文法模型到統計模型,再到神經網絡模型的演變,其中大規模預訓練語言模型(如GPT、BERT)成為主流。
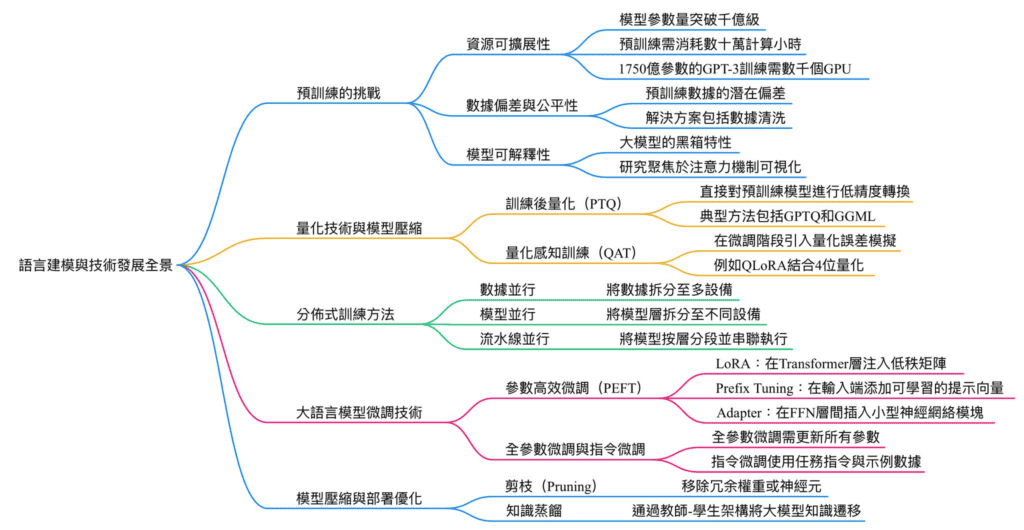
預訓練的挑戰
資源可擴展性:
隨著模型參數量突破千億級,預訓練需消耗數十萬計算小時與數百萬元成本,且能源消耗驚人。例如,1750億參數的GPT-3訓練需數千個GPU數月時間,凸顯分佈式計算與高效算法的重要性。
數據偏差與公平性:
預訓練數據的潛在偏差(如性別、文化偏見)會直接影響模型輸出。研究表明,未經校正的數據可能導致模型生成歧視性內容。解決方案包括數據清洗、去偏置算法設計,以及引入公平性評估指標。
模型可解釋性:
大模型的黑箱特性使得決策過程難以追溯。研究聚焦於注意力機制可視化、特徵歸因分析等方法,以提升透明度和可信度。
量化技術與模型壓縮
量化技術通過降低參數精度(如32位浮點轉為8位整數)來縮減模型體積並加速推理,分為兩大類:
訓練後量化(PTQ):直接對預訓練模型進行低精度轉換,無需額外訓練,適用於快速部署。典型方法包括GPTQ(基於梯度更新的量化)和GGML(混合精度量化)。
量化感知訓練(QAT):在微調階段引入量化誤差模擬,提升模型對低精度運算的適應性,例如QLoRA結合4位量化與LoRA微調,可在消費級GPU上運行650億參數模型。
量化技術的效能取決於權重分佈的敏感度,極端低精度(如2-bit)可能導致性能顯著下降,需搭配稀疏化或混合量化策略。
分佈式訓練方法
分佈式訓練透過並行化解決單一設備的計算與內存限制,主要分為三種策略:
數據並行:將數據拆分至多設備,各設備持有完整模型副本並同步梯度,適用於參數量適中的模型。
模型並行:將模型層拆分至不同設備,常用於超大型模型(如Megatron-Turing的萬億參數架構),需解決跨設備通信開銷問題。
流水線並行:將模型按層分段並串聯執行,結合微批次(Micro-batching)隱藏通信延遲,典型框架包括PyTorch的PipeDream。
分佈式訓練的實作需搭配集合通信庫(如NCCL)、參數伺服器架構,以及彈性容錯機制以應對節點故障。
大語言模型微調技術
參數高效微調(PEFT)
PEFT技術僅微調少量參數即可適應下游任務,顯著降低計算成本:
LoRA(Low-Rank Adaptation):在Transformer層注入低秩矩陣,通過矩陣分解模擬參數更新,保留原始權重。
Prefix Tuning:在輸入端添加可學習的提示向量(Prefix),引導模型生成任務相關輸出,適用於生成任務。
Adapter:在FFN層間插入小型神經網絡模塊,僅訓練適配器參數,保持主幹網絡凍結。
全參數微調與指令微調
全參數微調需更新所有參數,雖性能最佳但成本高昂,常用於領域適配(如法律、醫療文本)。指令微調(Instruction Tuning)則使用任務指令與示例數據,增強模型遵循複雜指令的能力。
模型壓縮與部署優化
剪枝(Pruning):移除冗余權重或神經元,分為結構化剪枝(移除整層或通道)與非結構化剪枝(移除單個權重),需搭配重訓練恢復性能。
知識蒸餾:通過教師-學生架構,將大模型知識遷移至輕量模型,例如TinyBERT在僅10%參數量下保持70%以上性能。
這些技術的組合應用(如量化+剪枝)可實現模型體積縮減10倍以上,同時維持90%以上的原始準確率。
Reference
[1] 加群链接: https://docs.qq.com/doc/DS3VGS0NFVHNRR0Ru#
[2] Transformer: https://arxiv.org/abs/1706.03762
[3] BLOOM: https://huggingface.co/docs/transformers/model_doc/bloom
[4] Parameter-Efficient Transfer Learning for NLP: https://arxiv.org/abs/1902.00751
[5] Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning: https://arxiv.org/abs/2012.13255
[6] Infused Adapter by Inhibiting and Amplifying Inner Activations: https://arxiv.org/abs/2205.05638
[7] P-Tuning论文: https://arxiv.org/abs/2103.10385
[8] P-Tuning V-2: https://arxiv.org/abs/2110.07602
[9] 思维链(CoT)提示: https://arxiv.org/abs/2201.11903
[10] PAL: Program-aided Language Models: https://arxiv.org/abs/2211.10435
[11] Distilling the Knowledge in a Neural Network: https://arxiv.org/abs/1503.02531