隨著生成式人工智慧(GenAI)與通用人工智慧(AGI)的快速發展,法律界也逐漸關注如何將這些技術應用於專業領域。本文將以白話方式解釋「知識蒸餾」的概念及其在法律與技術領域的潛在應用,並針對相關技術進行補充說明。
一、什麼是 #知識蒸餾?
知識蒸餾(Knowledge Distillation)是一種模型壓縮技術,旨在將大型、複雜的人工智慧模型(稱為「教師模型」)的知識,轉移到較小的模型(稱為「學生模型」)。這種技術的核心目的是在降低計算資源需求的同時,保留模型的高效能。
二、核心原理
1、#教師模型(Teacher Model):通常是參數規模龐大的模型,具備強大的綜合能力,例如 GPT-4、Gemini 2.0 等。
2、#學生模型(Student Model):較小的模型,透過學習教師模型的輸出來提升效能。
3、#蒸餾過程:教師模型對輸入數據進行推理,生成的輸出(例如分類概率分布或文本生成結果)被用作學生模型的訓練數據。
三、簡單比喻
可以將知識蒸餾比喻為「濃縮咖啡」的製作過程:將一大壺咖啡(教師模型的知識)濃縮成一小杯濃縮咖啡(學生模型),既保留了風味,又減少了體積。
四、知識蒸餾的應用場景
1、開源與本地模型
1)開源大模型:如 Llama 系列、DeepSeek 等,允許開發者下載並在本地部署,進行進一步的訓練或微調。
2)本地化應用:開源模型可作為基礎模型,經過知識蒸餾後,生成適合特定需求的小型模型,例如法律文件分析助手。
2、#法律領域的應用
1)法律文本生成與分析:透過蒸餾技術,將大型模型的能力壓縮到專用模型,用於生成法律意見書、合同草案或進行法律條文檢索。
2)隱私與合規性:在法律領域,數據隱私至關重要。知識蒸餾允許模型在不共享原始數據的情況下進行訓練,符合數據保護法規(如 GDPR)。
3、主權 AI 的發展
主權 AI:強調以本地數據訓練模型,確保數據主權與隱私安全。知識蒸餾技術可幫助國家或企業建立符合本地需求的 AI 系統。
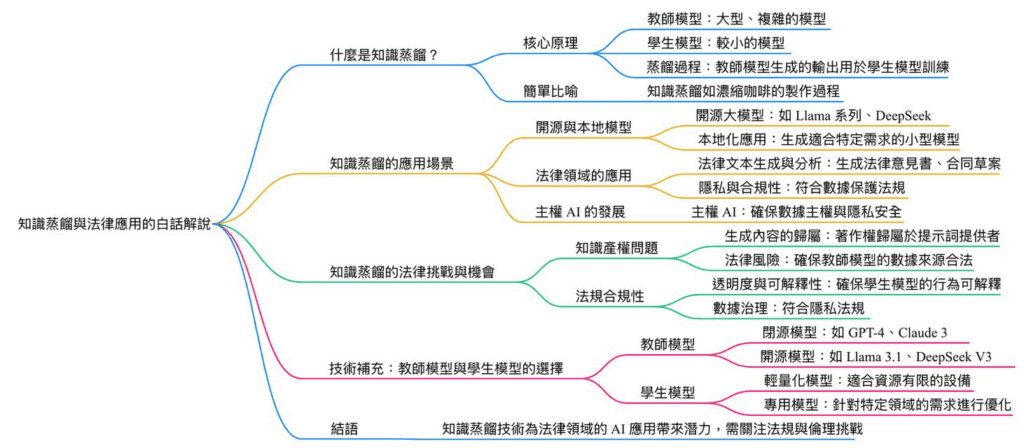
1、智慧財產權問題
1)#生成內容的歸屬:目前多數國家認為,生成式 AI 的輸出不構成著作,除非提示詞本身具有創意性,否則著作權歸屬於提示詞的提供者,而非模型擁有者。
2)#法律風險:在使用蒸餾技術時,需確保教師模型的數據來源合法,避免侵犯第三方權利。
2、法規合規性
1)透明度與可解釋性:歐盟《人工智慧法案》(AI ACT)要求生成式 AI 提供透明的內容標識,知識蒸餾技術需確保學生模型的行為可解釋。
2)數據治理:蒸餾過程中的數據處理需符合隱私法規,特別是在醫療、金融等敏感領域。
1)教師模型
• 閉源模型:如 GPT-4、Claude 3,通常以 API 形式提供,適合用於高效能的蒸餾過程。
• 開源模型:如 Llama 3.1、DeepSeek V3,允許開發者自由下載並進行本地化應用。
2)學生模型
• 輕量化模型:經過蒸餾後的學生模型,適合部署在資源有限的設備上(如手機或邊緣設備)。
• #專用模型:針對特定領域(如法律、醫療)的需求進行優化,提升應用價值。
六、結語
知識蒸餾技術為法律領域的 AI 應用帶來了巨大的潛力,特別是在提升效率、降低成本以及保護隱私方面。然而,法律人需在技術應用的同時,關注相關的法規與倫理挑戰,確保技術的使用符合專業精神與社會責任。
參考資料:
1. https://www.ailabs.tw/……/2025-taiwan-ai-industry……/
2. https://fion.news/?pn=vw&id=a1hd73f8raj3
3. https://genaistars.org.tw/news
4. https://www.cio.com.tw/85091/
5. https://hkaift.com/……/%E7%9F%A5%E8%AD%98%E8%92%B8……/
6. https://www.twba.org.tw/……/6266483a-18eb-40e8-9eee……
7. https://hackathon.lawsnote.com/
8. https://jamespolik.pixnet.net/blog/post/346991431