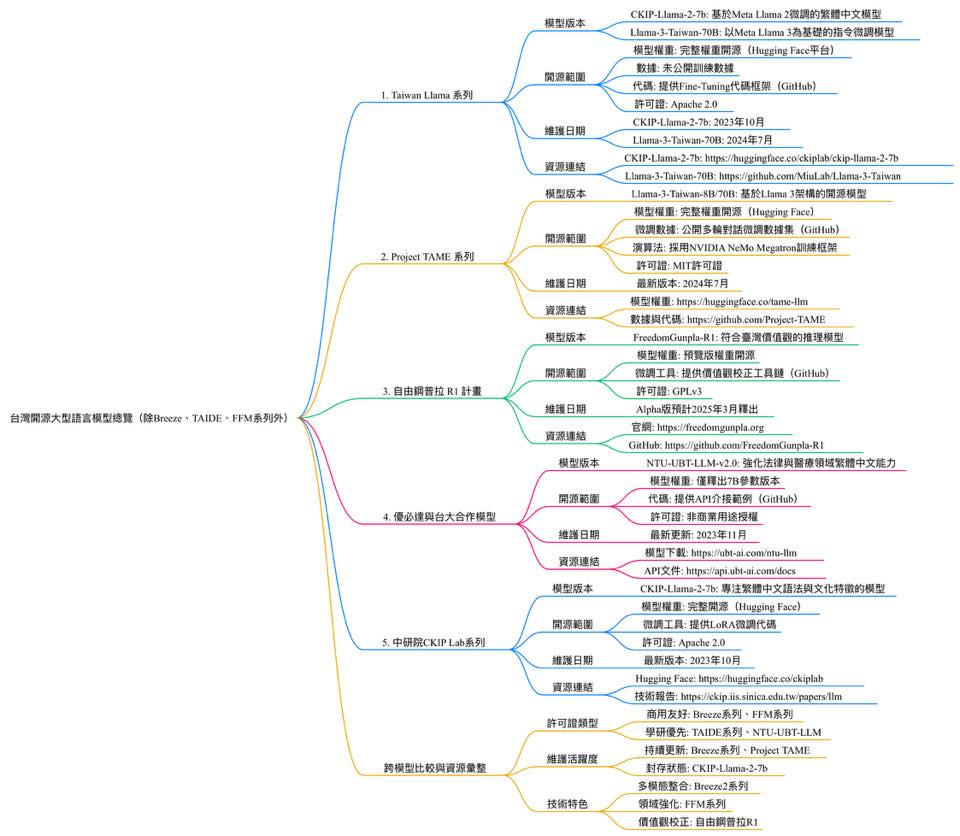
1. Taiwan Llama 系列
1)模型版本
Llama-3-Taiwan-70B:以Meta Llama 3為基礎,經繁體中文語料強化訓練的指令微調模型。
2)開源範圍
模型權重:完整權重開源(Hugging Face平台)。
數據:未公開訓練數據,但採用臺灣本土語料強化微調。
代碼:提供Fine-Tuning代碼框架(GitHub)。
許可證:Apache 2.0(商用需遵守Meta原始授權)。
3)維護日期
Llama-3-Taiwan-70B:2024年7月
4)資源連結
Llama-3-Taiwan-70B:https://github.com/MiuLab/Llama-3-Taiwan
2. Project TAME 系列
1)模型版本
Llama-3-Taiwan-8B/70B:基於Llama 3架構,經5,000億繁體中文Token連續預訓練的開源模型。
2)開源範圍
模型權重:完整權重開源(Hugging Face)。
微調數據:公開多輪對話微調數據集(GitHub)。
演算法:採用NVIDIA NeMo Megatron訓練框架。
許可證:MIT許可證(可商用)。
3)維護日期
最新版本:2024年7月
4)資源連結
模型權重:https://huggingface.co/tame-llm
數據與代碼:https://github.com/Project-TAME
3. 自由鋼普拉 R1 計畫(招募中)
1)模型版本
FreedomGunpla-R1:民間發起的開源計畫,目標打造符合臺灣價值觀的推理模型,基於DeepSeek架構。
2)開源範圍
模型權重:預覽版權重開源(計畫官網)。
微調工具:提供價值觀校正工具鏈(GitHub)。
許可證:
3)維護日期
Alpha版預計2025年3月釋出
4)資源連結
GitHub:https://github.com/FreedomGunpla-R1
4. 優必達與台大合作模型
1)模型版本
NTU-UBT-LLM-v2.0:由台灣大學與優必達聯合開發,強化法律與醫療領域繁體中文能力。
2)開源範圍
模型權重:僅釋出7B參數版本(學術用途)。
代碼:提供API介接範例(GitHub)。
許可證:非商業用途授權。
3)維護日期
最新更新:2023年11月
4)資源連結
模型下載:https://ubt-ai.com/ntu-llm
API文件:https://api.ubt-ai.com/docs
5. 中研院CKIP Lab系列(封存狀態)
1)模型版本
CKIP-Llama-2-7b:專注繁體中文語法與文化特徵的模型,強化文學創作能力。CKIP-Llama-2-7b:基於Meta Llama 2微調的繁體中文模型,由中研院CKIP Lab開發。
2)開源範圍
模型權重:完整開源(Hugging Face)。
微調工具:提供LoRA微調代碼。
許可證:Apache 2.0(商用需額外授權)。
3)維護日期
最新版本:2023年10月
4)資源連結
Hugging Face:https://huggingface.co/ckiplab
技術報告:https://ckip.iis.sinica.edu.tw/papers/llm
CKIP-Llama-2-7b:https://huggingface.co/ckiplab/ckip-llama-2-7b
6、跨模型比較與資源彙整
1)許可證類型
商用友好:Breeze系列(Apache 2.0)、FFM系列(Apache 2.0)
學研優先:TAIDE系列(非商業授權)、NTU-UBT-LLM(學術限制)
2)維護活躍度
持續更新:Breeze系列(2025年Llama-Breeze2)、Project TAME(2024年7月)
封存狀態:CKIP-Llama-2-7b(2023年後未更新)
3)技術特色
多模態整合:Breeze2系列整合視覺語言模型與函式呼叫
領域強化:FFM系列針對金融與醫療領域優化
價值觀校正:自由鋼普拉R1強調臺灣文化過濾機制