![]() 黑 DeepSeek 的「模型蒸餾」究竟是什麼?
黑 DeepSeek 的「模型蒸餾」究竟是什麼? ![]() (下完指令後,由ChatGPT4o生成臉書文)
(下完指令後,由ChatGPT4o生成臉書文)
最近,DeepSeek 在大模型圈子裡掀起了不少討論,而所謂的「模型蒸餾(Model Distillation)」究竟是怎麼一回事?這篇文章詳細解析了這項技術的原理與落地過程!
![]() 文章出處
文章出處 ![]() https://mp.weixin.qq.com/s/TAdBy7NBA4ypCsKJkCUyYQ
https://mp.weixin.qq.com/s/TAdBy7NBA4ypCsKJkCUyYQ
簡單來說,模型蒸餾是一種知識提取技術,它的核心思想是讓 小型「學生模型」學習大型「教師模型」的行為,從而在保留性能的同時,大幅減少計算需求與存儲空間。
![]() 關鍵步驟:
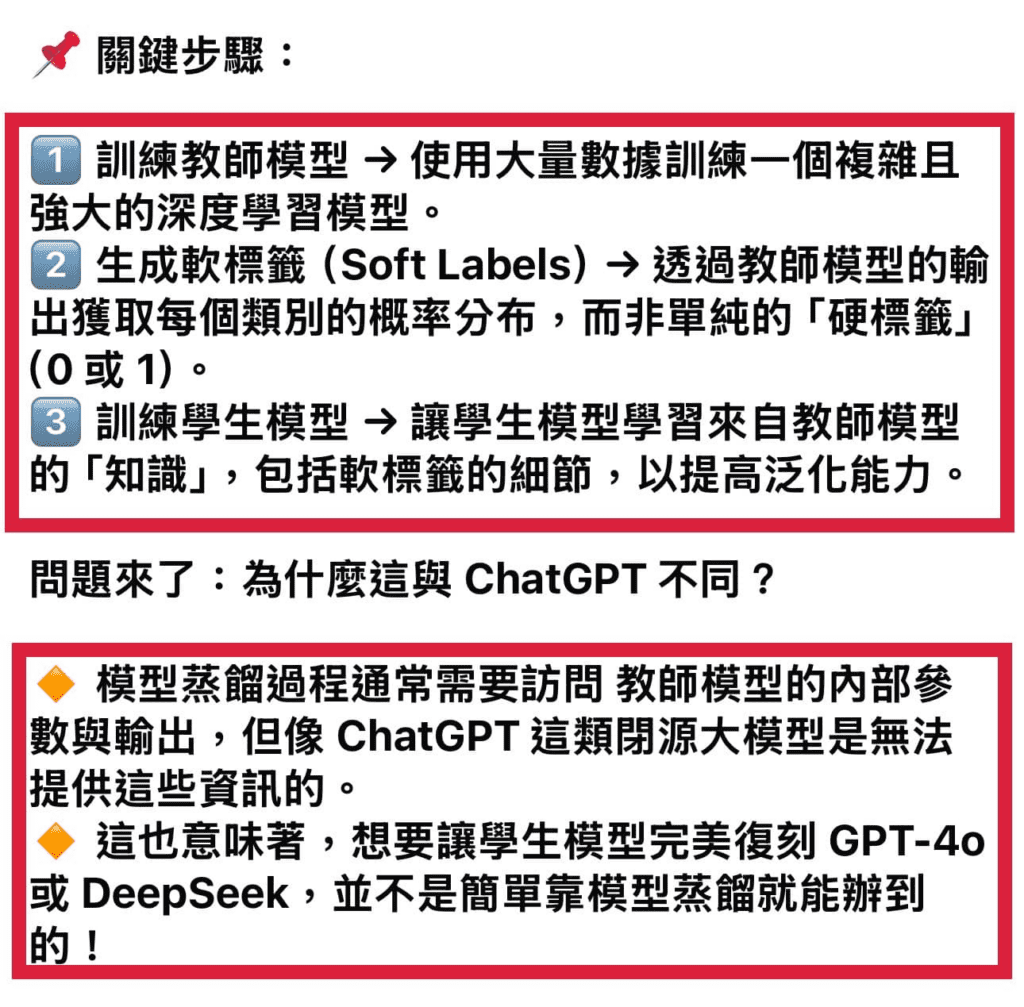
關鍵步驟:
![]() 訓練教師模型 → 使用大量數據訓練一個複雜且強大的深度學習模型。
訓練教師模型 → 使用大量數據訓練一個複雜且強大的深度學習模型。
![]() 生成軟標籤(Soft Labels) → 透過教師模型的輸出獲取每個類別的概率分布,而非單純的「硬標籤」(0 或 1)。
生成軟標籤(Soft Labels) → 透過教師模型的輸出獲取每個類別的概率分布,而非單純的「硬標籤」(0 或 1)。
![]() 訓練學生模型 → 讓學生模型學習來自教師模型的「知識」,包括軟標籤的細節,以提高泛化能力。
訓練學生模型 → 讓學生模型學習來自教師模型的「知識」,包括軟標籤的細節,以提高泛化能力。
問題來了:為什麼這與 ChatGPT 不同?
![]() 模型蒸餾過程通常需要訪問 教師模型的內部參數與輸出,但像 ChatGPT 這類閉源大模型是無法提供這些資訊的。
模型蒸餾過程通常需要訪問 教師模型的內部參數與輸出,但像 ChatGPT 這類閉源大模型是無法提供這些資訊的。
![]() 這也意味著,想要讓學生模型完美復刻 GPT-4o 或 DeepSeek,並不是簡單靠模型蒸餾就能辦到的!
這也意味著,想要讓學生模型完美復刻 GPT-4o 或 DeepSeek,並不是簡單靠模型蒸餾就能辦到的!
![]() 完整技術解析
完整技術解析 ![]() https://mp.weixin.qq.com/s/TAdBy7NBA4ypCsKJkCUyYQ
https://mp.weixin.qq.com/s/TAdBy7NBA4ypCsKJkCUyYQ