(與Felo Research多輪對話後生成的提示詞)
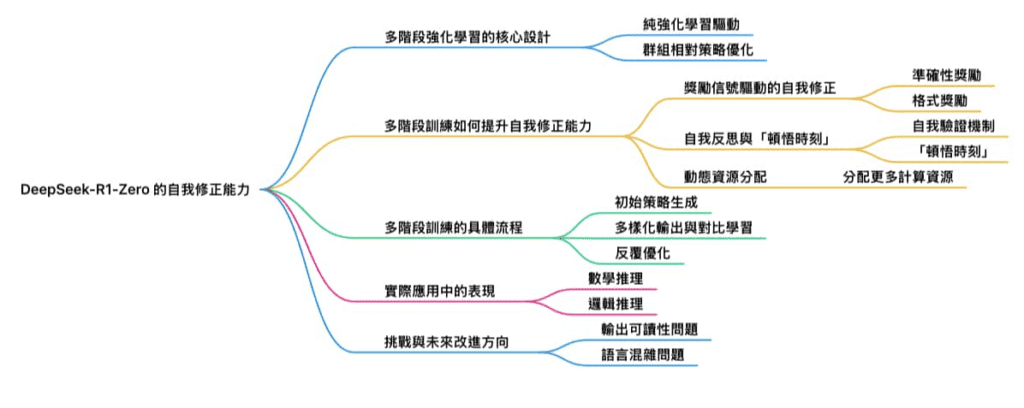
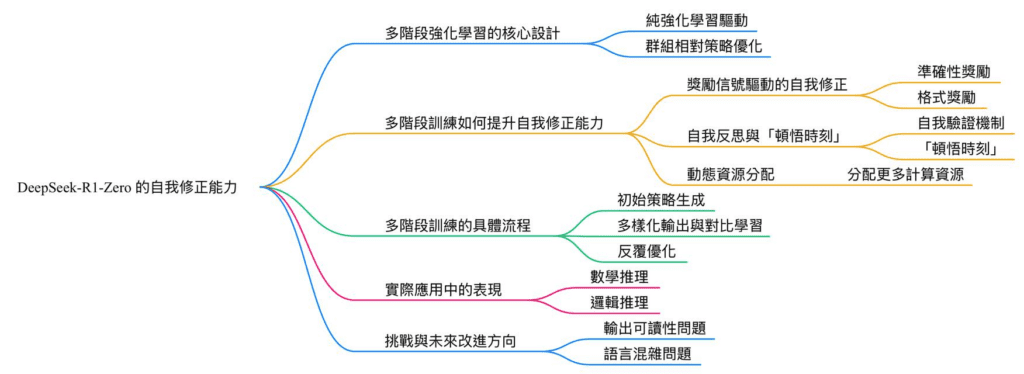
多階段強化學習訓練是 DeepSeek-R1-Zero 展現自我修正能力的核心技術之一。這種訓練方法透過分階段的設計,逐步提升模型的推理能力、自我檢查能力以及錯誤修正能力。以下是多階段強化學習如何實現這一目標的詳細解析:
1. 多階段強化學習的核心設計
DeepSeek-R1-Zero 的多階段強化學習訓練流程旨在讓模型逐步掌握推理與自我修正能力,並解決傳統訓練方法的不足。其主要特點包括:
純強化學習驅動:DeepSeek-R1-Zero 完全依賴強化學習(Reinforcement Learning, RL),不使用監督微調(Supervised Fine-Tuning, SFT),直接從預訓練模型(DeepSeek-V3-Base)進行訓練。
群組相對策略優化(Group Relative Policy Optimization, GRPO):這是一種專為 DeepSeek 設計的強化學習算法,通過對比同一問題的多個解答,根據預定規則(如準確性和格式)分配獎勵,從而引導模型生成更高質量的輸出。
2. 多階段訓練如何提升自我修正能力
多階段強化學習的設計讓模型能夠逐步學會檢查和修正自己的輸出,以下是具體的實現方式:
(1) 獎勵信號驅動的自我修正
準確性獎勵:模型在生成答案時,會根據其正確性獲得獎勵。例如,在數學推理中,模型需要生成符合規則的正確答案,否則會受到懲罰。這種機制促使模型在生成過程中主動檢查每一步推理是否正確。
格式獎勵:模型需以清晰的格式表達其推理過程,例如使用 <think> 和 </think> 標籤來標記思維鏈。這不僅提升了輸出的可讀性,也讓模型更容易檢查自己的邏輯是否一致。
(2) 自我反思與「頓悟時刻」
自我驗證機制:模型在推理過程中會主動檢查已生成的內容是否符合邏輯。例如,在解決邏輯謎題時,模型會回溯並重新評估其推理步驟,確保最終答案正確。
「頓悟時刻」(Aha Moment):在強化學習過程中,模型自然湧現出一種自我反思的能力,能夠在發現錯誤後重新思考並修正。例如,在解決「農夫過河」問題時,模型最初生成了一個錯誤的解法,但隨後通過重新評估邏輯,找到了正確的解法。
(3) 動態資源分配
分配更多計算資源:模型在處理複雜問題時,會自動分配更多的「思考時間」來進行深度推理,這種行為是強化學習過程中自然湧現的結果。
3. 多階段訓練的具體流程
DeepSeek-R1-Zero 的多階段強化學習流程如下:
初始策略生成:基於 DeepSeek-V3-Base 模型,使用 GRPO 算法生成初始策略,並通過多次試錯學習如何解決問題。
多樣化輸出與對比學習:對同一問題生成多個解答,並根據預定規則(如準確性和格式)分配獎勵,模型學習如何生成更高質量的答案。
反覆優化:模型在每次生成答案後,會根據獎勵信號調整其策略,逐步提升推理能力和自我修正能力。
4. 實際應用中的表現
數學推理:在數學問題中,DeepSeek-R1-Zero 能夠檢查每一步計算,並在發現錯誤時重新計算。例如,在 AIME 測試中,模型通過多次自我修正將正確率顯著提升。
邏輯推理:模型能夠檢查其邏輯推理是否一致,並在必要時重新生成部分內容。例如,在解決複雜邏輯問題時,模型會先生成初步答案,然後檢查其合理性,若發現不一致則進行修正。
5. 挑戰與未來改進方向
儘管多階段強化學習顯著提升了 DeepSeek-R1-Zero 的自我修正能力,但仍存在一些挑戰:
輸出可讀性問題:模型生成的推理過程可能過於冗長或混亂,影響用戶體驗。
語言混雜問題:在多語言環境中,模型可能會混用不同語言,導致表達不一致。
為了解決這些問題,後續版本(如 DeepSeek-R1)引入了冷啟動數據和多階段訓練流程,進一步提升了模型的推理性能與表達能力。