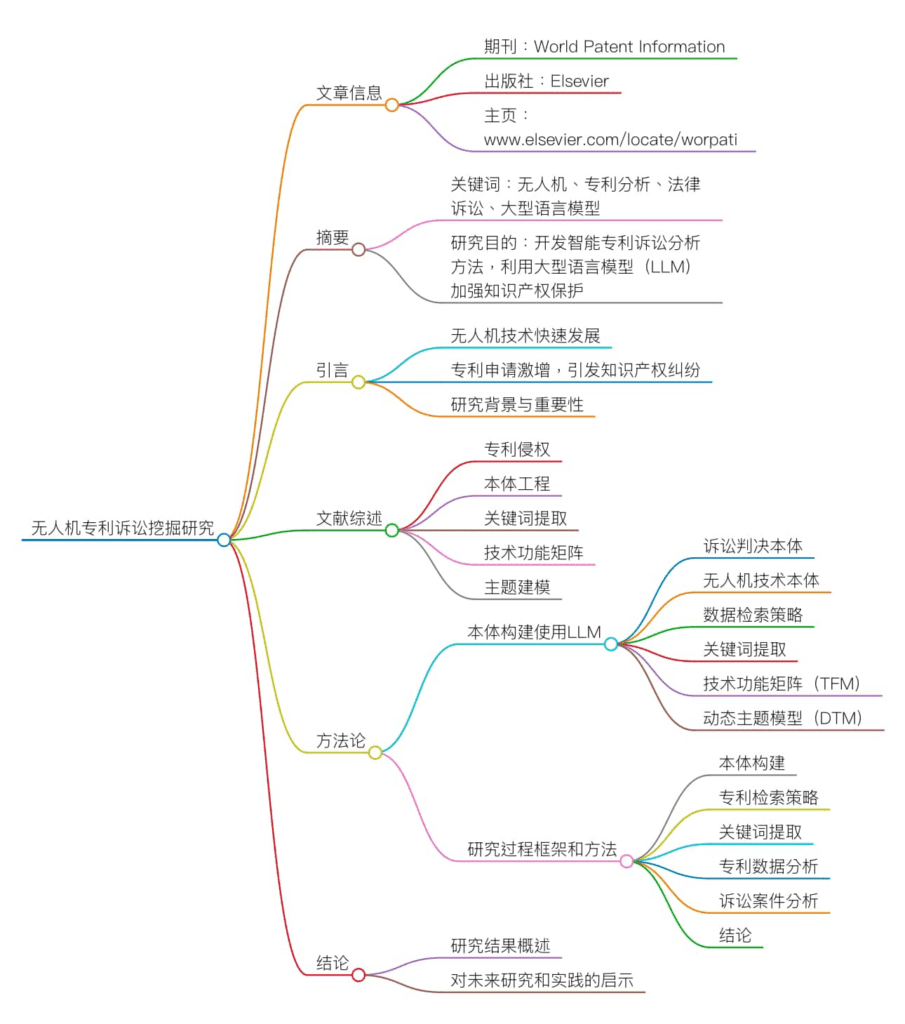
1. 研究背景與目的
隨著科技發展,專利訴訟在技術競爭中成為企業的重要戰略手段。尤其是在快速增長的技術領域(如無人機),專利糾紛的頻率和複雜性大幅提高。該論文基於專利和訴訟數據,提出了一套自動化主題分析框架,結合動態主題建模(Dynamic Topic Modeling, DTM)與科技功能矩陣(Technology Function Matrix, TFM),用於多層次的技術趨勢與訴訟焦點分析。然而,現有框架主要依賴於傳統數據分析技術,尚未整合大型語言模型(LLM)進行全面的自動化應用。
本文以該論文的框架為基礎,進一步建議開發一個名為 Agentic System 的系統,以更高層次的自動化和智能化實現專利訴訟的全流程分析,涵蓋訴訟前、中、後的關鍵環節,為企業提供決策支持。
2. 主題分析框架
該論文的核心貢獻在於提出一套基於數據驅動的主題分析框架,結合 DTM、TFM 和語義分析工具(如 KeyBERT、CorEx)對專利與訴訟數據進行結構化處理與分析。
2.1 宏觀層面分析
2.1.1識別技術趨勢與關鍵技術領域(如導航系統、通信技術)。
2.1.2提取專利申請量、技術分佈與主要申請人(如 DJI、大疆創新)。
2.2 微觀層面分析
2.2.1聚焦具體專利的訴訟焦點,通過主題建模分析爭議技術與專利範圍。
2.2.2將訴訟過程與技術發展趨勢結合,預測未來可能的風險點。
3. 使用大語言模型可以改進的方向
該框架以傳統的數據分析技術為核心,但尚未整合大型語言模型(LLM)以進一步提升自動化能力。本文建議在該框架基礎上引入 LLM,實現以下改進:
3.1 知識本體構建
3.1.1使用 LLM 分析專利與訴訟文本,構建專利訴訟的知識圖譜。
3.1.2精確提取技術與法律要點,提升語義理解的精確性。
3.2 關鍵詞提取與主題聚類
3.2.1結合 KeyBERT 提取關鍵詞,輔助模型進行技術主題分類。
3.2.2利用 CorEx 提高技術和法律文本的可解釋性。
上述改進能大幅提升主題分析框架的智能化與實用性,為構建 Agentic System 提供技術基礎。
4. Agentic System 的構想
基於該論文提出的主題分析框架,本文建議開發一個 Agentic System,結合 LLM 與自動化分析技術,實現專利訴訟的全流程支持,涵蓋訴訟前的風險預測與布局、訴訟中的焦點提取與分析、以及訴訟後的策略優化。
4.1 系統目標
4.1.1訴訟前:風險預測與技術布局
1)分析競爭對手的專利組合與歷史訴訟行為,預測潛在風險。
2)幫助企業優化研發策略,避免侵權風險。
4.1.2訴訟中:主題提取與案例支持
1)自動提取法律文本爭議焦點,關聯歷史案例,提供決策支持。
2)通過主題建模跟蹤案件進展,生成即時分析報告。
4.1.2訴訟後:趨勢分析與策略優化
1)分析裁決結果對技術發展的影響。
2)幫助企業優化專利組合,識別潛在技術布局機會。
4.2 系統組成
4.2.1數據處理模組:支持多語言專利與法律文檔的數據抓取、清洗與結構化處理。
4.2.2主題建模模組:基於 DTM 和 CorEx 捕捉技術與法律主題的時序變化。
4.2.3智能分析模組:使用微調的 LLM 自動生成技術分析報告與訴訟風險評估。
4.2.4用戶界面(UI):簡單直觀的操作界面,支持法律專家輸入案件資料並獲取分析結果。
5. 開發 Agentic System 的建議路線圖
5.1 團隊組成
5.1.1法律專家: 負責需求定義與結果驗證。
5.1.2機器學習工程師: 開發與微調主題建模和語義分析模型。
5.1.3數據科學家: 負責專利與法律數據的處理,確保數據質量。
5.1.4軟件工程師: 開發用戶界面與系統集成。
5.2 開發階段
5.2.1初期(0-3 個月):
1)建立數據管道,完成基礎數據清洗與結構化。
2)運行 KeyBERT 和 DTM 模型進行初步分析。
5.2.2中期(4-9 個月):
1)微調 LLM(如 LLaMA-7B)以適應法律與技術文本。
2)開發 TFM 進行跨領域主題分析。
5.2.3後期(10-18 個月):
1)完成系統集成,提供實時訴訟風險評估功能。
2)通過用戶測試優化系統性能與界面。
6. 總結與未來展望
6.1該論文提出的主題分析框架為專利訴訟的數據處理與趨勢分析提供了有力工具。本文進一步建議開發 Agentic System,將該框架與 LLM 結合,實現專利訴訟的全面自動化分析,助力企業在技術競爭中取得優勢。
6.2未來改進方向包括:
6.2.1強化 LLM 在多語言專利與訴訟數據處理中的應用,提升跨語言語義分析的準確性。
6.2.2引入多模態數據(如專利圖像與文本),拓展框架的分析範圍與實用性。
6.2.3持續優化 Agentic System 的模型性能,確保其穩定性與精度,並提升其在實際應用中的價值。
《Patent litigation mining using a large language model—Taking unmanned aerial vehicle development as the case domain》
https://authors.elsevier.com/a/1kKNodA7TlyRJ
補語:
一、論文作者提出了一種方法論,透過 #構建本體(ontology)並使用 K-means 和 CorEx #主題模型 來分析 #專利訴訟數據。具體來說,作者使用了 #動態主題建模(Dynamic topic modeling)和 #科技功能矩陣(Technology Function Matrix, TFM)等技術手段,對無人機行業的專利資訊進行了宏觀和微觀層面的分析。
二、開發階段(PLSoP:Pipeline, LLM, Smart System, Optimization, Production)
為確保各階段目標的有效執行,應在5.2 開發階段的每一階段中明確設定 Benchmark(基準測試)、Milestone(里程碑) 和 POC(概念驗證)。以下是詳細規劃:
5.2.1初期(0-1 個月):Pipeline 建立與基礎分析
5.2.1.1 主要目標:
1)建立數據處理管道,完成基礎數據清洗與結構化處理。
2)使用現有工具,運行 KeyBERT 和 DTM 模型進行初步分析主題分析,驗證分析框架的可行性。
5.2.1.2 Benchmark:
1)數據清洗準確率達 95%(驗證數據完整性與一致性)。
2)關鍵詞提取模型(KeyBERT)的精確度不低於 85%。
5.2.1.3 Milestone:
1)建立一條穩定的數據管道,可處理多語言專利與法律數據。
2)完成專利數據的初步主題提取和結構化分析。
5.2.1.4 POC:構建一個小規模概念驗證數據集(包含 100 篇專利文件與 50 篇訴訟文本),測試數據清洗和初步分析框架的效能。
5.2.2. 中期(2-3 個月):LLM 微調與智能體系統測試
5.2.2.1 主要目標:
1)微調大型語言模型(LLM,如LLaMA-7B),以適應專利與法律文本的特定需求。
2)開發科技功能矩陣(TFM),完成跨領域主題分析功能。
3)啟動智能體系統的內部測試與市場測試,收集用戶反饋並優化系統。
5.2.2.2 Benchmark:
1)微調後的 LLM 能夠準確識別 90% 的專利術語與法律要點。
2)主題建模工具(如 DTM 和 CorEx)在時序分析中的準確度達 88%。
2)智能體系統的市場測試滿意度不低於 80%。
5.2.2.3 Milestone:
1)完成基於專利數據的 LLM 微調(例如LLaMA-7B)。
2)開發並驗證科技功能矩陣(TFM)的準確性和可解釋性。
3)啟動智能體系統的第一輪市場測試,收集來自 10-15 名測試用戶的反饋。
5.2.2.4 POC:構建一個具備完整功能的小型智能體系統原型,對至少 50 篇專利和 20 篇訴訟文本進行風險評估測試。
5.2.3. 後期(4-6 個月):系統集成與優化
5.2.3.1 主要目標:
1)完成智能體系統的集成與優化,實現訴訟風險評估的自動化與即時分析功能。
2)通過全面用戶測試,完成系統性能與界面優化。
3)正式推出產品並進行早期客戶導入。
5.2.3.2 Benchmark:
1)系統的全流程自動化準確率不低於 92%。
2)系統界面可用性測試(Usability Testing)得分不低於 85 分。
3)系統平均分析處理時間小於 5 秒。
5.2.3.3 Milestone:
1)完成智能系統的全功能集成,包括數據處理、主題建模和風險評估模組。
2)經過多輪用戶測試後,系統性能達到商業化標準。
3)成功導入首批企業用戶(5-10 家),並提供技術支持與應用培訓。
5.2.3.4 POC:在早期客戶導入環境下,對 100 個專利案例和 50 起訴訟進行完整測試,驗證系統的商業可行性。
5.2.4總結規劃
• Benchmark 確保每階段的技術指標清晰可量化。
• Milestone 為關鍵進展設定具體成果目標,評估項目進展情況。
• POC 用於快速驗證概念與技術的可行性,降低後期技術風險。
該規劃結合 Benchmark、Milestone 和 POC,建立了一套完整的開發流程,確保在縮短時程的同時,提升開發過程中的質量控制與商業化可行性。
是否創建了一個大型語言模型(LLM)來實現這一過程的自動化。